Vision Transformer论文解读
发表于ICLR2021的Vision Transformer已经成为后续Transformer模型在CV领域进一步发展的基石,本文为初代Vision Transformer论文An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale的解读。
Vision Transformer的pytorch实现可以看我放在Github里的实现:Vision Transformer pytorch - Github,欢迎前来star&fork✨✨✨
Why
首先就是为什么要设计Vision Transformer?过往CV领域基本上主要就是CNN的各种变体的天下,可以说对CNN的依赖非常之深。而由于Transformer在NLP领域的大放异彩,大家都在研究如何使用新的模型代替CNN之前的工作。

将Transformer移植到CV领域的一个问题是,NLP领域里,一个句子的长度不会长到无法处理,但是CV领域的一张224*224的图片展开就长达50,176,将这样长的序列输入到Transformer里是无法完成的任务😥!将图像展开成一维数组会导致输入长度平方增长,这是将图像输入到Transformer要解决的首要问题。
所以正如论文里所说,研究者们尝试了许多种不同的方法来解决这个问题,比如仅仅在局部邻域应用注意力机制,亦或是轴注意力等方式减少计算量,除此之外还有将图像拆分成2*2patch的方法(其实这个思路已经近乎等同于Vision Transformer了)等等。
Structure of Vision Transformer
下图就是论文中Vision Transformer的结构:
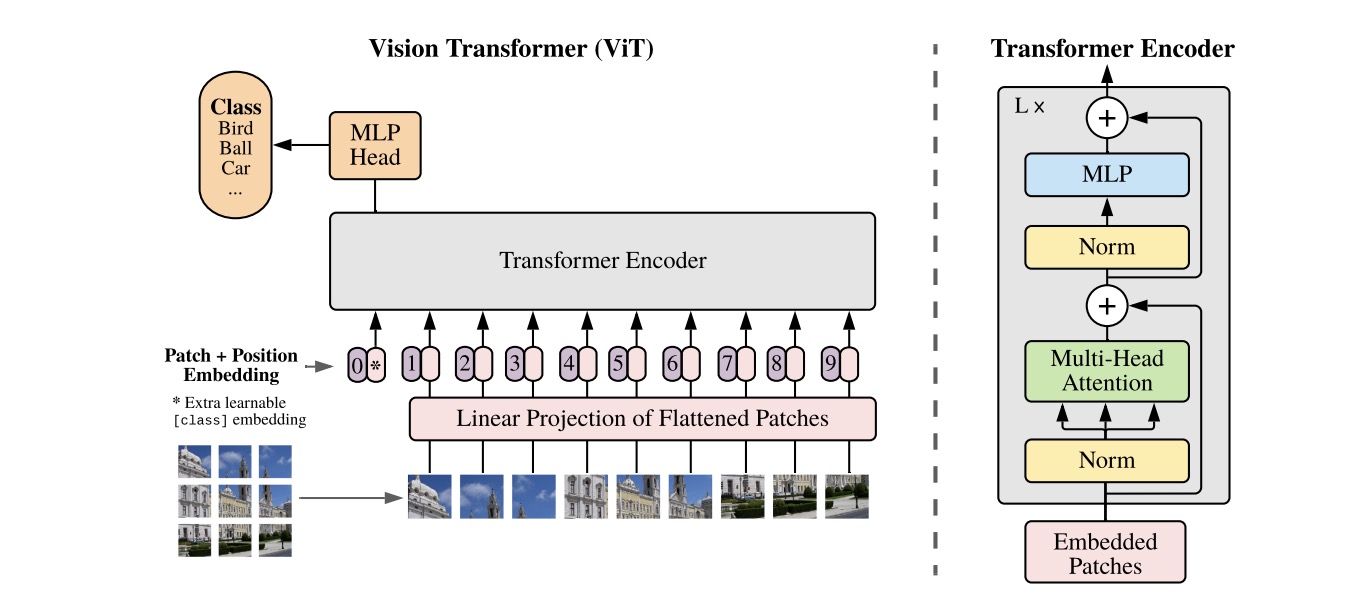
结构解读:
①Patching:首先Vision Transformer将图片分割成n*n个patch,这样每个patch展开的长度就很大程度地缩小了。e.g.假设图像是224*224大小,设定每个patch的大小为16*16,那么图像就分割成了14*14个patch,并且每个大小为16*16的patch展开之后为256,这个大小就是模型可以处理的了!
②Position Embedding:如图,patch之后使用一个Linear Projection层将所有patch映射,其实这里就是所有patch过了一个线性层。然后将过了线性层的所有patch进行位置编码,这里一开始我也不知道是怎样生成的位置编码,但其实就是每个位置随机生成的位置编码,并且这个编码是可训练的,后面会进一步说一下位置编码的问题。
(另外,在实现中,patching + linear projection的操作可以等价于一个kernel size和stride都等于patch size的Conv2D。这个也很好理解,就是每次卷积核裁出一个patch size的patch,然后再走这么多的步长,就相当于分割了patch,最后卷积层的运算就相当于线性层。所以基本上这步用一个kernel size和stride都等于patch size的Conv2D卷积层就可以做到!)
③Class Token:这里还有一个cls token,这个方法其实源自Bert模型。根据原文,最后MLP Head分类的时候也只使用cls token中的信息。但是其实使用cls token或者不使用cls token转而对所有Encoder的输出进行全局平均池化,个人认为没有什么太大的区别,因为其实cls token本质就是“窥探”地综合了所有patch的信息。
④Transformer Encoder:Vision Transformer中其实没有Decoder结构,只使用Encoder。这里我们可以将其与Transformer的结构进行对比来发现Vision Transformer的改进。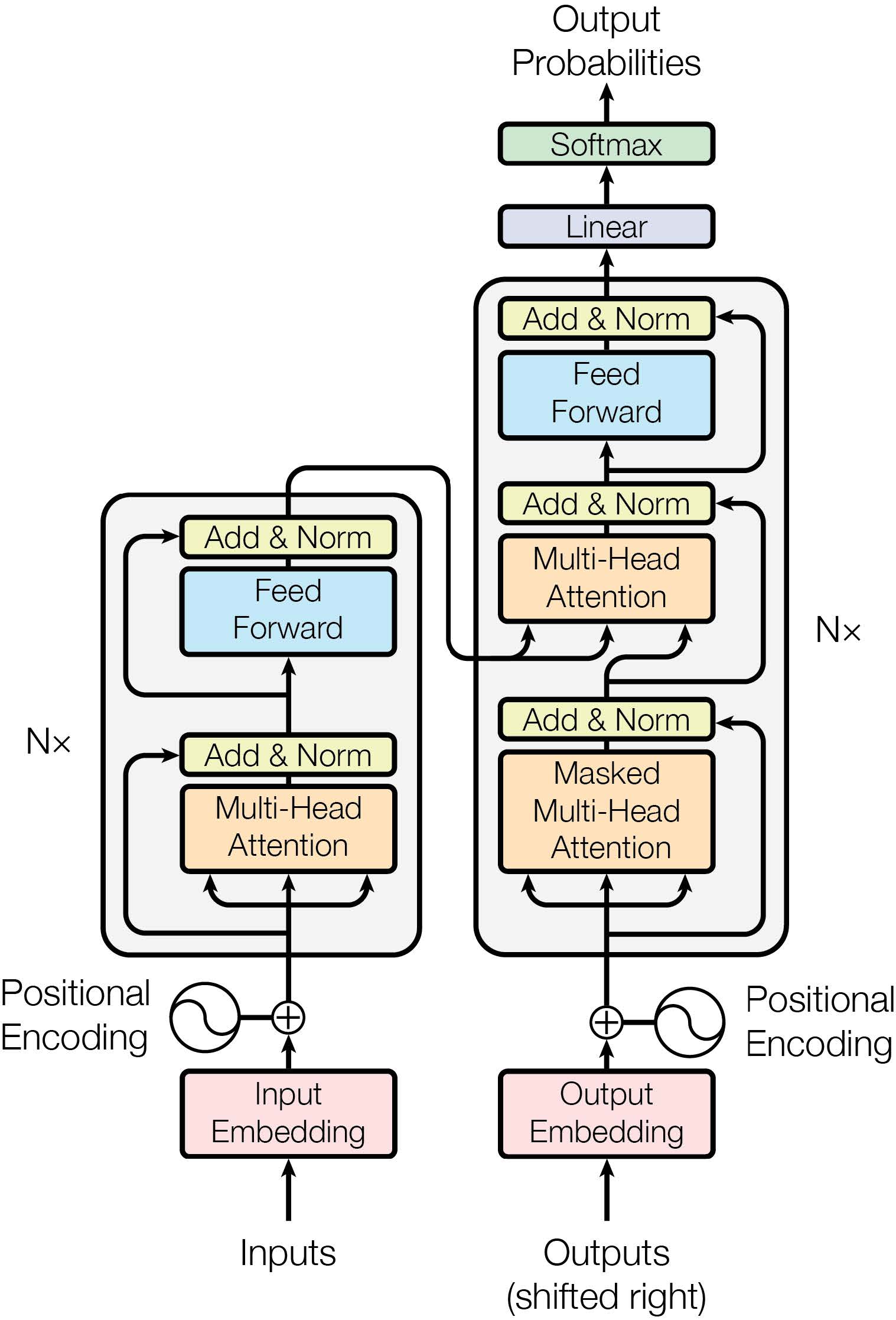
其实整体和NLP的原Transformer Encoder的结构非常相似,作者也是尽可能在最小程度修改原模型的程度上将Transformer应用到CV领域来。一个小的区别是两个Layer Norm在Encoder中的位置提前了。
输入进入Layer Norm层,后接一个多头自注意力机制,一个残差结构,后面又是一个Layer Norm层,接一个MLP,一个残差结构。这就构成了一个ViT的Encoder Block,然后可以按所需要的网络深度堆叠多个。
⑤MLP Head:正如前面所说,原文只使用cls token的输出作为MLP Head的输入进行分类。但是使用池化我认为也是可以的,因为无论如何只要MLP Head可以获得到整体的特征信息即可。
SOTA, inductive bias and training from scartch
论文是Google Brain和Google Research的团队做的,计算资源那是相当滴丰富(羡慕羡慕羡慕羡慕好羡慕🤤🤤🤤)。
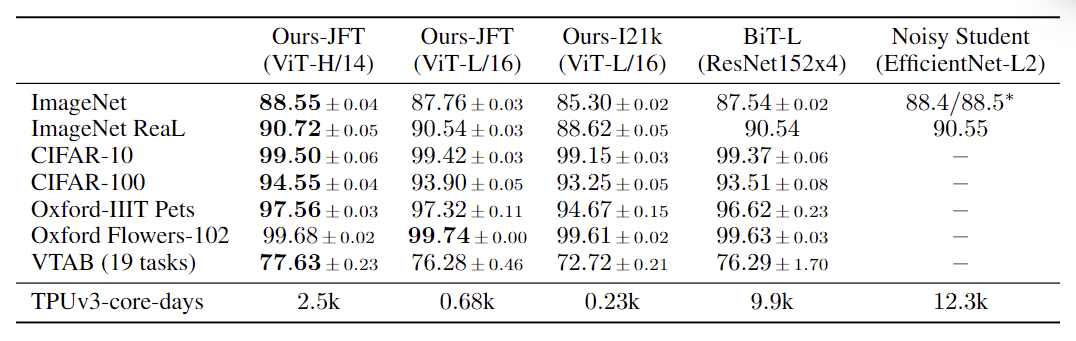
可以看出,在大型数据集上预训练的ViT模型可以完爆之前的巨型CNN——ResNet152x4了,效果确实有非常明显地提升,是当时的state of the art了。
但是代价是什么呢?不同于CNN中的卷积结构,Transformer完全没有inductive bias(归纳偏置)。卷积层本身就具有的translation equivariance(平移等价性)和locality(局部性),Transformer是完全没有的。所以相当于这部分东西就得模型自己去学习😥,这一定程度就是位置编码的工作了。
论文做了非常多的实验,其中就包括位置编码,比如1D位置编码(也就是上面所说的)、2D位置编码、Rel.位置编码、没有位置编码的对比实验等。最后发现只要有位置编码,无所谓是哪种位置编码的,效果都差不多其实。因为位置编码最后无论如何都能学习出来2D的特征,这也涉及到另一个实验——位置编码的余弦相似度那个实验,见下图中间那个小图:

(该实验就是计算在模型经过训练之后,不同位置的位置编码之间的余弦相似度。该实验的复现也可见我们的Github仓库:Position embedding similarity。另有RGB filter的实验复现(即上图中第一个小图):RGB filter)
可以看到,其实最后通过位置编码的学习,可以获得到这部分inductive bias,但与此同时,这需要大量的且更general的图像数据集和大规模的训练支撑,在Google JFT300M这种超超超超大数据集上预训练的效果才是最好的,这意味着这会比CNN结构的网络消耗更多的资源和更多的时间。简而言之,Vision Transformer还是非常难以训练的,因为需要大量的成本去训练。
后续的另一篇论文Three things everyone should know about Vision Transformers也有更多的实验和研究。与其你在数据集上training from scartch(从0开始训练),不如拿预训练好的模型直接fine-tune(微调)。Training from scartch不仅消耗更多的资源,而且效果还不如在超大训练集上预训练后微调的模型。总的来说,迁移模型然后fine-tune才是你要做的。
尾巴
总的来说,Vision Transformer打破了CNN在CV领域的垄断局面,但是也具有非常明显的问题,毕竟工业界不是为了刷点,工业界也需要轻量可部署的模型。但是Vision Transformer也算是一个重要的开端✨,后续产生了非常多的Vision Transformer变体,比如和CNN结合,比如在其他CV任务的应用,效果都非常非常好。
我写这篇解读距离我亲手搭建已经过去了一段时间,所以难免可能会有一些勘误或者表达不准确的地方,欢迎读者指出,我将感激不尽😊😊😊。
References
Vision Transformer: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Transformer: Attention Is All You Need
Bert: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Three things of ViT: Three things everyone should know about Vision Transformers
ResNet: Deep Residual Learning for Image Recognition
BiT: Big Transfer (BiT): General Visual Representation Learning
Vision Transformer论文解读